

Enterprise Level Machine Learning Tools & Tips: Part 2
Part 2: Machine Learning System Lifecycle.
I'm a senior full-stack developer, and I love software engineering. I believe by working together we can create wonderful assets for the world, and we can shape the future as we shape our own destiny, and no goal is too ambitious. 💫 I try to be optimistic and energetic, and I'm always open to collaboration. 👥 Contact me if you have something on your mind and let's see where it goes 🚀
Implementing an ML solution is different from a general feature that is going to be added to a system. It needs a careful and flexible system design from loading data to fetching predictions. In this article, I'm going to note down an ML model lifecycles, necessary steps, and some important notes to watch out for.
Machine Learning Lifecycle Overview
Designing and implementing a Machine Learning system consists of 3 major phases, each with 3 subsections:
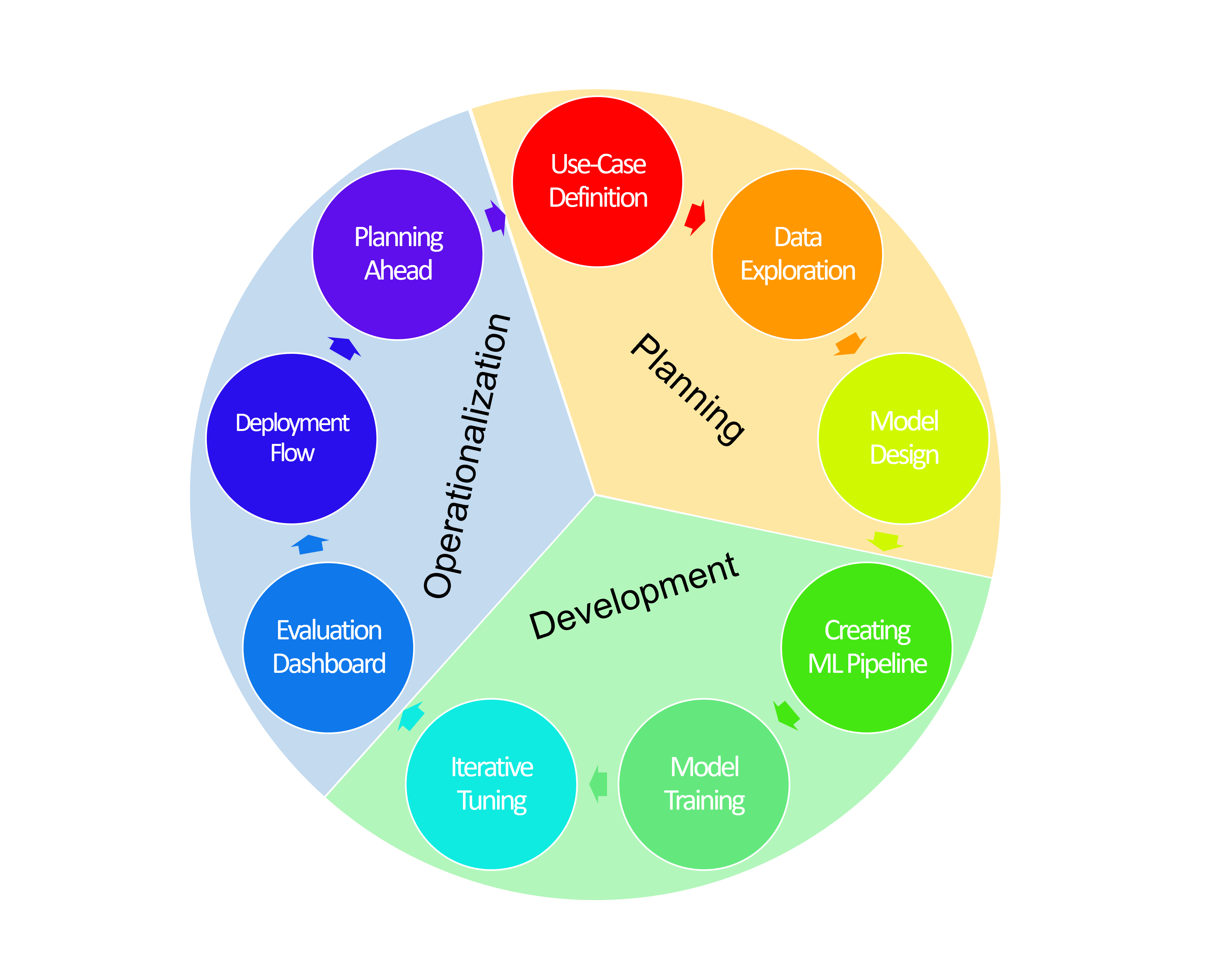
I'll be defining each phase in the following sections:
Planning
This phase is the most important and should be thoroughly and extensively discussed. Business strategies must be considered with a technical mindset and practical applications should be identified.
1.1. Use-Case (Problem) Definition
First and foremost, sections of the business for which an AI is expected to improve must be identified. We've heard of suggestive and predictive models, but any functionality that is based on rules or follows some patterns (as obscure as they may be) can be automated by machine learning. How a subject is framed, will impact all the next steps from the data pipeline to building a model.
An AI is supposed to automate a process, so a process has to exist in the first place, and a solid one for that matter. For the ML to be counted as an improvement upon something, a foundational data-driven algorithm has to be first designed, implemented, and tuned.
Note
In a technical sense, these goals will be defined as labels.
1.2. Data Preparation
Accessibility
During the second step, the availability of valid data sources must be investigated, after all, an ML solution is feasible only when data is accessible in enough size and variance. Also, depending on the use case, the accessibility of the data sources must be assessed. For example, if a real-time suggestion system is to be implemented, perhaps access to some user data at recommendation time has to be first ensured.
Many projects attempted to create an ML model and went through the design and development without proper data analysis & preparation. Thus considerable resources were spent, only for the model to fail at the training and evaluation phases because of a lack of valid data.
Relevancy
Not all the attributes of a dataset are needed for the workflow of a machine learning model. It's best to pluck out the relevant features/fields using different analysis methods such as:
Principal Component Analysis (PCA)
Is a popular technique for analyzing large datasets containing a high number of dimensions/features per observation, increasing the interpretability of data while preserving the maximum amount of information. Hence, PCA is considered a reduction technique for reducing the dimension of datasets. This is accomplished by linearly transforming the data into a new coordinate system where (most of) the variation in the data can be described with fewer dimensions than the initial data.
(Source)
Tips
PCA is an unsupervised approach, and it is a valid method of feature selection only if the most important variables are the ones that also have the most variation. This is usually not true, and disregarding the last few components is likely to decrease model performance.
PCA is at a disadvantage if the data has not been standardized before applying the algorithm to it. PCA transforms original data into data that is relevant to the principal components of that data, which means that the new data variables cannot be interpreted in the same ways that the originals were. They are linear interpretations of the original variables. Also, if PCA is not performed properly, there is a high likelihood of information loss.
If a dataset has a pattern hidden inside it that is nonlinear, then PCA can actually steer the analysis in the complete opposite direction of progress.
Correlation Analysis
Correlation Analysis is a statistical method that is used to discover if there is a relationship between two variables/datasets, and how strong that relationship may be.
The following formula is the most widely used non-parametric correlation analysis formula, which measures the strength of the ‘linear’ relationships between the raw data from both variables:$$r = \frac{\Sigma(x-\bar{x})(y-\bar{y})}{\sqrt{\Sigma(x-\bar{x})^2}\sqrt{(y-\bar{y})}}$$
$$Where\ \bar{x}\ is\ the\ mean\ value\ of\ x\ and\ \bar{y}\ is\ the\ mean\ value\ of\ y$$
Tips
I highly suggest studying the
sourceif you're interested in learning moreThe principle is to remove two sets of features
Those that do not correlate much to the objective (label)
Those that correlate highly to other attributes (features)
1.3. Model Design
Based on the use case and available resources, a proper model has to be selected from pre-built available online services or designed from scratch. Usually, if the company or the development team does not have a deep understanding of Data Engineering and Machine Learning concepts, it's best to start with a managed machine learning online service to first evaluate or create a proper strategy that involves machine learning techniques for improving the relevant KPIs. Delving straight into machine learning when the project doesn't have the required foundations might lead to devastating setbacks, and you might not get the results you expect on the first try.
Online Managed ML services
By separating the necessary technical designs and offering a catalog structured around functionality and practicality, instead of the technical aspects of engineering a model, online managed ML services offer a fast solution that depending on the goals of the business, can be considered a short-term or a long-term asset to the company. Some of such services are:
Tip
- It's best to take on this phase of the project with an experiment-based approach until the proper data and request pipelines are in place. Multiple approaches have to be tested until the right model is found; notably, getting help from experts in the Machine Learning field can keep the number of iterations low.
Custom ML Models
Although describing the architecture of all available ML models is not possible in just one article, and it's also off-topic, I would like to take note of two aspects of model design:
Dimension
Deep Models
Prioritize generalization, which is based on the transitivity of correlation, investigates new feature combinations that have never or rarely happened in the past.
These models have deep layers and embedding layers which produce embedded connections between the previous layer's output (features) and predict based on those embeddings, which can lead to invisible connections between options and produce something unexplored according to the fed dataset.
Wide Models
Prioritize memorization, which is learning about the frequent co-occurrence of elements or traits and making use of correlations found in historical data.
The use of transformations of crossing products on sparse items allows for efficient memorization. Using entity transformations between products, wide linear models can efficiently record sparse entity interactions.
It's important to note that these architectural designs are not opposed to one another and they are used hand-in-hand and parallel to each other in some scenarios to make the best of generalization and memorization to provide the best of both worlds.
Recurrency
Feedforward Networks (FNN)
In these networks, the connections between nodes don't form a loop, and so each layer is fed information only from the previous layers and passes information only to the next layers, hence creating a one-directional data processing pipeline.
The models are usually used for classification problems.
Recurrent Networks (RNN)
In these networks, the connections between nodes form a loop, and so the information can be passed from later layers to the earlier ones. In other words, they use their reasoning from previous experiences to inform upcoming events.
These networks are quite adept at inferring the next probable inputs from the previous ones, hence they are used for language processing and speech recognition; both of these applications, demand a chain of correlating inputs to be processed sequentially.
Development
2.1. Creating ML pipeline
A pipeline is a series of tasks that are carried out to arrive at a concluding result from a predefined set of inputs. Every application has a pipeline that is run by the incoming requests and results in an expected response. Machine learning systems require a separate pipeline(s) for carrying out all the necessary operations to perform a classification or prediction based on a set of input attributes. I think of this pipeline in 3 major parts:
Data Pipeline
Handles the ETL process of data which are: Extract, Transform, Load
This is the part where the data is gathered from different data sources (E), and split into training, evaluation, and testing datasets. They are then transformed from raw data to features adhering to a specified dataset schema and it's usually called preprocessing (T), and they are shuffled and handed over to the other part of the data pipeline (L). The data pipeline can be separate from other sections and it can be run locally while the rest of the process that involves training and evaluation can be carried out in a cloud environment, it all comes down to your desired setup.
ETL process has many steps and many algorithms that we won't cover in this article.
Training Pipeline
This is the part where the preprocessed training data is used for training the model.
During and after each successful pipeline run, you should log the statistical info of input, the status of training, training time, achieved metrics, and evaluation result by comparing the performance of the trained model with the evaluation dataset.
It's very important for this process not to be destructive, as you should always keep a version of the old trained and validated model version, for comparing the performance, spotting anomalies in data, and for the possible redeployment of a previous version if the desired criteria were not met after training.
Overseer Pipeline
This is the part where the health check of each component of the pipeline is performed by regular checkups and error reporting is done. This part is optional and in managed ML platforms, it's usually integrated into the last 2 parts as a default.
Tips
One of the important aspects of working with user data with any business strategy is how to handle Personal Identifiable Information (PII). This information should be kept a secret from the other users, most admins, unnecessary services, and most response headers and bodies. However, since these attributes might provide a valuable learning opportunity for our models in identifying user-related patterns, we should incorporate this information into the training process somehow. The best way to do so is by tokenizing a set of attributes with a key-based hashing system, that produces unique labels that are not created by a deterministic encryption algorithm; because the anonymization process has to be irreversible.
For saving and loading a model you can refer to
tf.saved_model
2.2. Building Model
After the model design is done and the proper ML pipeline is ready, the next step is to train the model. This can be used from UI if you're using managed services such as GCP: Vertex AI platform or AWS: Amazon Personalize but it has to be coded if you're going to use your own model.
Basically, this section is already covered in the training pipeline but I would like to state some notes for the training process in this relevant section:
Underfitting
When a statistical model or machine learning algorithm fails to accurately predict the data's underlying trend, this is referred to as underfitting. An obvious sign of underfitting is a high training error rate and high evaluation error rate.
How to Avoid Underfitting
Clean datasets before starting the training and evaluation. Make sure NaN values (outliers) and noises are properly covered.
Increase the model complexity to match the complexity of the problem.
Adjust hyperparameters.
Overfitting
When a statistical model or machine learning algorithm completely memorizes the training set instead of just learning the underlying patterns, overfitting has happened. Overfitting can only be recognized by comparing the performance on training with evaluation datasets; if the model has a high accuracy and low error rate on the training dataset but has a low accuracy and a high error rate on the evaluation dataset, then we can be sure overfitting has occurred.
How to Avoid Overfitting
Clean datasets before starting the training and evaluation. Make sure repetitive features that do not contribute to the training process are deleted from the dataset.
Provide enough training samples and make sure enough variance exists in the feature values.
Reduce the model complexity to match the complexity of the problem.
Adjust hyperparameters.
Regularization
Is a process that encourages the resulting answer to be "simpler", hence reducing the chances of overfitting. Concluding the training and allowing the model to settle on the achieved weights faster, will save RAM and time, and reduces noises in error charts.
Regularization may help with improving the performance of a model by zeroing out the weights of less relevant features. However, if only the relevant features are already fed to the model, then introducing regularization might not improve the model's performance, but it may help with reducing the training time.
L₂ Regularization
Penalizes weights by
w²(derivative:2*w)Since the derivative (reduction-trend) is percentage-based, the weights will never reach 0.
Helps with collinearity.
L₁ Regularization
Penalizes weights by
|w|(derivative:n)Since the derivative is a constant, the weights might cross 0, after which the weights are zeroed out by the L₁ regularization.
Is recommended for wide models, because it helps with sparsity.
2.3. Iterative Tuning
The ML model trains some parameters (aka weights) on each epoch but there are some parameters that we should set before the training starts and they affect the training time, and resulting performance. These parameters are called hyperparameters.
Depending on the model architecture, these hyperparameters describe different points in the structure of a model. "Searching" for the right hyperparameter values can be quite time-consuming. As the model is trained, the optimum value of each one might change, hence one should regularly monitor the model's performance. Also, there isn't a straightforward mathematical way of calculating these values. So what should one do?
Well, while there are some methods, all of them are quite time-consuming. So my suggestion is to first study each hyperparameter thoroughly and try to answer the following questions
How does this hyperparameter affect the model's architecture?
What does it represent in the predictive model?
What logical minimum and maximum values could it take?
Now hopefully, you have found an estimated range (or at best, a starting point) for each of the hyperparameters. The next step is to use a method to pinpoint the optimum value for each:
Discrete Search
In this method, also called Grid Search, we specify a range for each hyperparameter and keep the first n-1 of them at one value while changing the nth term, each time the model is trained, and the best value according to specified evaluation metrics, is chosen. Then we change the (n-1)th term and keep the unevaluated ones constant, while setting the evaluated ones to the found optimum value.
While the values of the hyperparameters are not necessarily discrete, it pays off to use this method to find one or several starting points for various combinations of hyperparameters.
Random Search
This method is quite similar to the previous one, with the difference being that the hyperparameter values are no longer discrete specified points, but rather values given by different statistical distribution functions. The superiority of this method in comparison to the last is pointed out beautifully in the following quote from JeremyJordan.
One of the main theoretical backings to motivate the use of random search in place of grid search is the fact that for most cases, hyperparameters are not equally important.
A Gaussian process analysis of the function from hyper-parameters to validation set performance reveals that for most data sets only a few of the hyper-parameters really matter, but that different hyper-parameters are important on different data sets*. This phenomenon makes grid search a poor choice for configuring algorithms for new data sets. -* Bergstra, 2012
Bayesian optimization
Bayesian optimization is a strategy for the global optimization of functions that is independent of any preassumptions in regard to what the function does or how it looks like. It is usually employed to optimize expensive-to-evaluate functions and it belongs to a family of optimization methods called Sequential Model Based Optimization.
Tips
- Bayesian optimization may help reduce the number of required iterations until reaching an acceptable result, but it does not necessarily mean that it is efficient time-wise. Because the trials are sequential and dependent on each other.
Note: I'm not going to go through more details about this but I suggest you read more about it.
Operationalizing
3.1. Creating Evaluation Dashboards
Defining an Evaluation Metric
The evaluation metric has to be selected according to the use-case definition:
Regression problems usually use errors.
Classification problems usually use precision, accuracy, and recall.
Conventional Errors
mean absolute error ❌
Poor at detecting variance because it gives the same weight to all errors.
mean squared error ✅✅
A good metric because it gives more weight to errors with larger absolute values than to errors with smaller absolute values.
root mean squared error ✅
Does not penalize high variance as much as mean squared error because the root operation reduces the importance of higher values.
Creating Conditional Alerts
As mentioned previously, you have to log the output of each step in the ML pipeline for future analysis and for the evaluation of the current pipe run. It's also good practice to set up alerts through emails, and other notifications (integration with Slack, etc.) to further improve your monitoring of the performance and the health of the models.
Comparing Against a Baseline Model
A baseline is a model with the same Dimension and Recurrency but with a less complex design; for example, with a reduced number of hidden layers.
Tips
- A baseline should aim to test statistically a model’s ability to learn by comparing it to a less complex data-driven approach. So it's important to keep the evaluation metrics, training goals, and assessment metrics the same between the two models.
3.2. Setup Deployment Flow
Regarding Incoming Requests
If the model has already been deployed and the recommendation/prediction system is connected to active clients, it's best if you keep an active and valid model up and running before all the evaluation metrics and training procedures are finished successfully, and the model is deemed ready for deployment. Even then, a blue/green or canary deployment is recommended, to reduce the downtime as much as possible.
Regarding Model
One of the important concepts in every pipeline is how the changes are going to be reflected in the workflow. If there's a critical change in the process or the schema of datasets, then you may have to update the necessary parts and train the model from scratch. If however, the changes do not target foundational definitions of the ML model, you can proceed with training the model as usual after the changes are applied to the workflow.
3.3. Planning Ahead
The final step is to let the model run as you keep monitoring its health, performance, and the impact of the prediction system as a whole, on the KPIs of the business. You can then introduce new features, increase the model's complexity, keep tuning hyperparameters, and also improve your API and the reach of your AI.
At this point, your system should be up and running. After deciding on the next improvement points, you should rerun this cycle from step 1.1.
Final Word
This marks the end of part 2. Many topics could've been explained in more detail but I tried to keep the information as concise and as relevant as possible. I hope this helps you get a better perspective on how to start an ML system. In the next part, I'll be covering some relevant GCP and AWS stack.
If you find this interesting, have a comment, or think a section needs more explanation, reach out to me and I'll do my best to be responsive.
