

DataOps: Data Build Tool (DBT)
A technical introduction to the Data Build Tool (DBT) data management platform, its features, and its integration capabilities.
I'm a senior full-stack developer, and I love software engineering. I believe by working together we can create wonderful assets for the world, and we can shape the future as we shape our own destiny, and no goal is too ambitious. 💫 I try to be optimistic and energetic, and I'm always open to collaboration. 👥 Contact me if you have something on your mind and let's see where it goes 🚀
Background
Three key concepts of maintaining data engineering projects are:
Versioning: You must always keep a history of the lineage of the data sources and data models that you use.
Testing: Like every other aspect of software development, data models need to be tested before the deployment to PRD.
Documentation: You should keep at least a minimal description of the functionality of each and the relationships between the data models.
For versioning and documentation most people use git platforms such as GitHub or GitLab. But a more comprehensive and easily manageable platform that is specifically data-oriented is needed, especially at an enterprise-level project. A popular example of such a platform is Data Build Tool (DBT).
Introduction
Per official documentation of dbt:
dbt™ is a SQL-first transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation. Now anyone on the data team can safely contribute to production-grade data pipelines.
Features
Modularization & Flexibility
Applying DRY principle in data analysis keeps the code clean, tidy, and structured. You can create data models and reference them in your other models.
You can write in SQL and Python DataFrames; no more DML and DDL!
You can use package management! You can easily include packages from snowplow, fivetran, as well as their own custom libraries. For a full list you can refer to this page.
Create seeders and test files for each model in the same package to make sure that the code will work as expected before and after deployment.
Documentation
Write version-controlled markdown-formatted detailed description of each data model or dbt package.
You can generate these docs automatically through dbt cloud as well!
You can host a dbt documentation website locally to have access to all the necessary information while engineering your data locally.
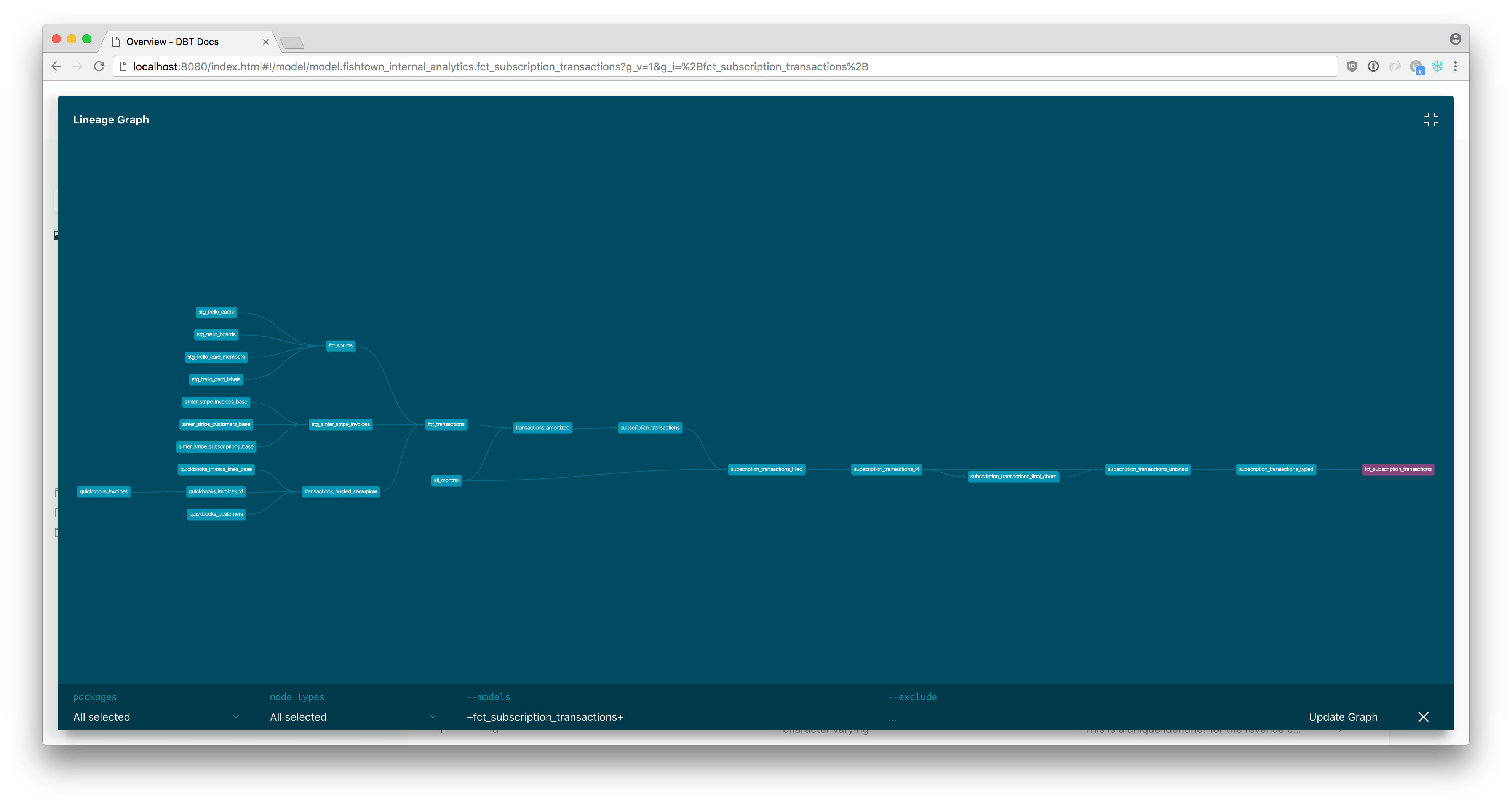
Show lineage graphs of your data models
The full lineage for a dbt model
(Source)
Optimization
Increase query performance by leveraging incremental models, a concept introduced by dbt. Basically, they're tables but for holding large amount of data that doesn't change drastically. The only rows that get updated/inserted are those that were changed before since the last data ingestion & transformation was conducted.
Branching, code review, and code (model & package) versioning are available as part of the dbt platform. The data team can easily incorporate all the best practices of design and development.
Easy integration of CI & CD tools.
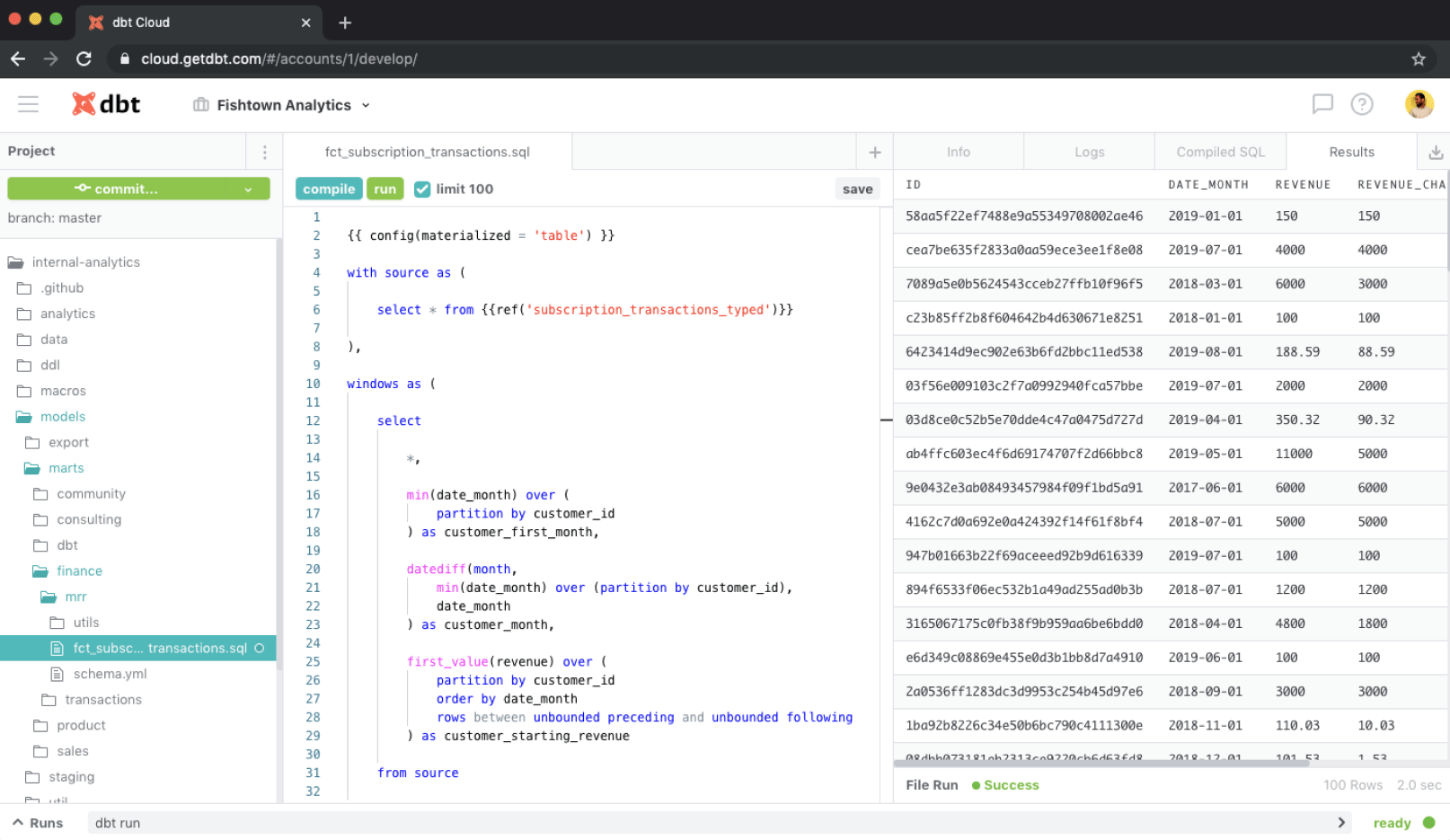
A comprehensive UI with online IDE capabilities that can show and format the package structure and dependencies, edit model files, with syntax highlighting and so much more.
(Source)
Integration
DBT supports db adapters which are a connector of some sort that allows dbt platform to perform CRUD operations on many dataplatforms (lakes, warehouses, databases, etc.). These are currently available official and community-developed adapters:
| Dataplatform | Official |
| AlloyDB | ✅ |
| Athena | ❌ |
| AWS Glue | ❌ |
| Azure Synapse | ✅ |
| BigQuery | ✅ |
| Clickhouse | ❌ |
| Databend Cloud | ❌ |
| Databricks | ✅ |
| Doris & SelectDB | ❌ |
| Dremio | ✅ |
| Dremio | ❌ |
| DuckDB | ❌ |
| Exasol Analytics | ❌ |
| fal - Python models | ❌ |
| Firebolt | ❌ |
| Greenplum | ❌ |
| Hive | ❌ |
| IBM DB2 | ❌ |
| Impala | ❌ |
| Infer | ❌ |
| iomete | ❌ |
| Layer | ❌ |
| Materialize | ❌ |
| MindsDB | ❌ |
| MySQL | ❌ |
| Oracle | ❌ |
| Postgres | ✅ |
| Redshift | ✅ |
| Rockset | ❌ |
| SingleStore | ❌ |
| Snowflake | ✅ |
| Spark | ✅ |
| SQL Server & Azure SQL | ❌ |
| SQLite | ❌ |
| Starburst & Trino | ✅ |
| Teradata | ❌ |
| TiDB | ❌ |
| Vertica | ❌ |
Disclaimer: The checkmarks and the cross icons do not represent any feelings nor do they necessarily judge the performance of these adapters. They're simply a means of conveying whether the contributor was an official source of the DBT team or not.
You can find online guides on how to leverage this powerful platform on popular infrastructures such as GCP, AWS, SnowFlake, and Azure.
Final Word
I hope this article served as a brief introduction to this powerful and trending data-engineering-oriented project development platform.
