

DataOps: Apache Airflow - Basic
Apache Airflow: A powerful workflow orchestration platform
I'm a senior full-stack developer, and I love software engineering. I believe by working together we can create wonderful assets for the world, and we can shape the future as we shape our own destiny, and no goal is too ambitious. 💫 I try to be optimistic and energetic, and I'm always open to collaboration. 👥 Contact me if you have something on your mind and let's see where it goes 🚀
Introduction
Apache Airflow is an open-source platform for authoring, scheduling, and monitoring data and computing workflows. It was developed by Airbnb and is now under the Apache Software Foundation.
It uses Python to create workflows that can be easily scheduled and monitored. Airflow's extensible Python framework enables you to build workflows connecting with virtually any technology. It is deployable in many ways, from a single process on a laptop to a distributed setup to support even the biggest workflows.
“Workflows as code” serves several purposes:
Dynamic: Airflow pipelines are configured as Python code, allowing for dynamic pipeline generation.
Extensible: The Airflow framework contains operators to connect with numerous technologies. All Airflow components are extensible to easily adjust to your environment.
Flexible: Workflow parameterization is built-in leveraging the Jinja templating engine.
Setup
Airflow is a python library and can be installed like any other. BUT that's not the recommended way. Why?
Well, airflow is more of a platform than just a normal python module. It needs a directory to keep some files, such as logs, as well as a database (default: Postgres) and a message broker (default: redis). All of this can be set up on your machine but the easier, cleaner way that is independent of the system you're working on is to use Docker.
Recommended docker-compose.yml file by the official docs is too complicated for anyone unfamiliar with airflow so it's recommended to download it from this link and just run it for starters using docker compose up -d.
If enough memory is not allocated to Docker engine, it might lead to the webserver continuously restarting. You should allocate at least 4GB of memory for the Docker Engine (ideally 8GB).
Next, you can bring up the admin panel by visiting the (default) 8080 port on your localhost. To log in, you can use the default credentials provided in the docker-compose.yml file:
username: airflow
password: airflow
Airflow’s user interface provides both in-depth views of pipelines and individual tasks, and an overview of pipelines over time. From the interface, you can inspect logs and manage tasks, for example retrying a task in case of failure.
Airflow uses Airflow Celery Executor to distribute workload between different Celery workers. You can use the --profile flower argument like docker compose --profile flower up -d to also fire up the Flower monitoring app to check up on the Airflow framework at the (default) port of 5555.
Limitations
Airflow was built for finite batch workflows. While the CLI and REST API do allow triggering workflows, Airflow was not built for infinitely-running event-based workflows. Airflow is not a streaming solution. However, a streaming system such as Apache Kafka is often seen working together with Apache Airflow. Kafka can be used for ingestion and processing in real-time, event data is written to a storage location, and Airflow periodically starts a workflow processing a batch of data.
If you prefer clicking over coding, Airflow is probably not the right solution. The web interface aims to make managing workflows as easy as possible and the Airflow framework is continuously improved to make the developer experience as smooth as possible. However, the philosophy of Airflow is to define workflows as code so coding will always be required.
Core Concepts
Macros
The Airflow system consists of these main components:
Scheduler
Handles triggering workloads on the specified schedule, and submitting tasks to the Executor.
Executor
There are two policies depending on the volume of expected task execution demand (generally Production ENV has heavy workloads while Development ENV is on the lighter side):
Lighter workloads: Runs tasks in its own container.
Heavier workloads: Distributes the tasks to workers.
The task distribution strategy is quite smart and efficient, as it will run tasks on whatever worker is available rather than assigning all the tasks of a DAG to a single worker.
Webserver
The aforementioned administrative UI allows monitoring, debugging, and rerunning of tasks and DAGs, by the admins.
DAGs
A folder of DAGs that is accessed by the Scheduler, and Executor (and its workers). You can also define Sub DAGs which allow for modularized reusable DAGs.
The serial nature of tasks that constitute the DAGs can be modified by branching, latest-only, and trigger rules.
DB
Data storage for keeping the metadata and state of components of the workflow, used by Scheduler, Executor, and Webserver.

Note
The serial nature of tasks that constitute the DAGs can be modified by branching, latest-only, and trigger rules.
We'll be discussing the aforementioned topics in a later article.
Micros
Tasks
A DAG runs a series of tasks. A task is traditionally, a separate set of commands that is executed in complete isolation* from other tasks. Though hard to distinguish with a clear-cut, there are three kinds of tasks according to the official documents:
Tasks have dependencies on other tasks, representing the priority by which they should be executed. Higher-priority tasks are called upstream and lower-priority tasks are called downstream.
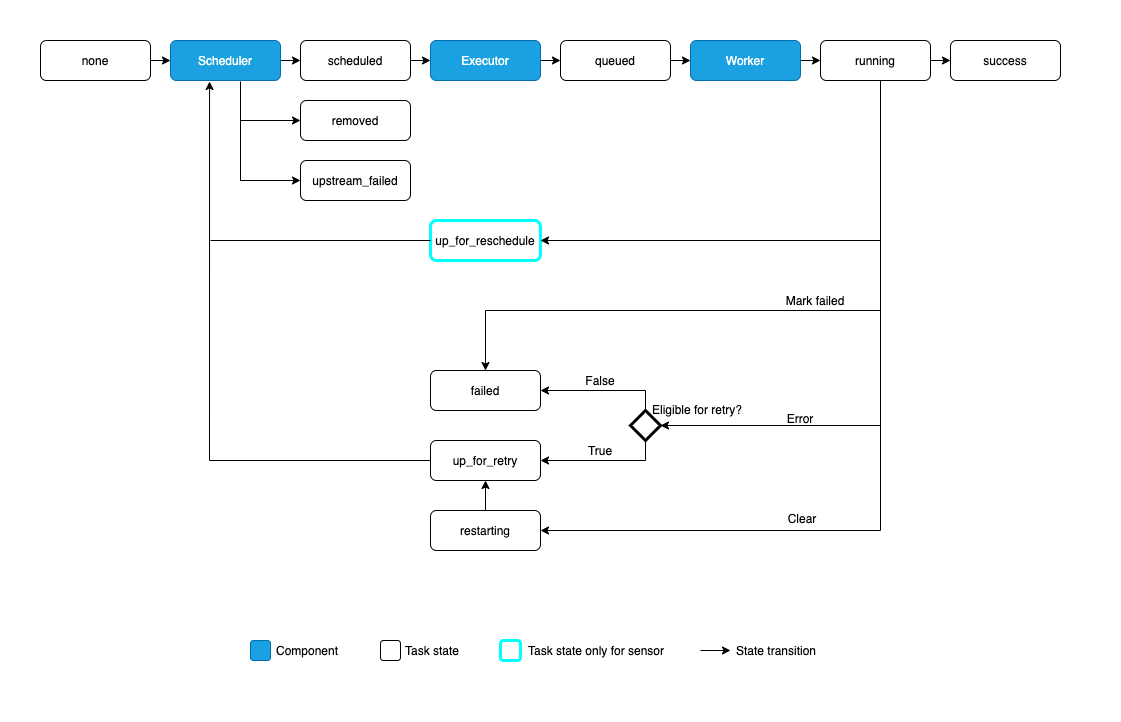
Status Legend
none: The Task has not yet been queued for execution (its dependencies are not yet met)
scheduled: The scheduler has determined the Task’s dependencies are met and it should run
queued: The task has been assigned to an Executor and is awaiting a worker
running: The task is running on a worker (or on a local/synchronous executor)
success: The task finished running without errors
shutdown: The task was externally requested to shut down when it was running
restarting: The task was externally requested to restart when it was running
failed: The task had an error during execution and failed to run
skipped: The task was skipped due to branching, LatestOnly, or similar.
upstream_failed: An upstream task failed and the Trigger Rule says we needed it
up_for_retry: The task failed, but has retry attempts left and will be rescheduled.
up_for_reschedule: The task is a Sensor that is inreschedulemode
deferred: The task has been deferred to a trigger
removed: The task has vanished from the DAG since the run started
There are also two additional unconventional but possible states for tasks:
Zombie tasks are tasks that are supposed to be running but suddenly died (e.g. the machine died). Airflow will find these periodically, clean them up, and either fail or retry the task depending on its settings.
Undead tasks are tasks that are not supposed to be running but are, often caused when you manually edit Task Instances via the UI. Airflow will find them periodically and terminate them
Operators
An Operator is conceptually a template for a predefined Task, that you can just define declaratively inside your DAG. There are many operators, and you can define your own custom ones. Here's a list of most popular ones:
BashOperator - executes a bash command
PythonOperator - calls an arbitrary Python function
EmailOperator - sends an email
SimpleHttpOperator
MySqlOperator
PostgresOperator
MsSqlOperator
OracleOperator
JdbcOperator
DockerOperator
HiveOperator
S3FileTransformOperator
PrestoToMySqlOperator
SlackAPIOperator
Sensors
Sensors are a special kind of operator that instead of running actively, wait for a trigger. They have two modes:
Poke: The sensor's designated worker runs continuously while checking for the trigger status.
Reschedule: The sensor is assigned a worker every time it's checking for the trigger, after which it enters a waiting period before checking again.
Timing
Tasks can have maximum valid execution_timeout, and if breached a AirflowTaskTimeout is raised and the task will stop running.
Additionally, there's a concept called SLA which stands for Service Level Agreement. Which is the maximum time that a task should be finished by then relative to the start time of the DAG.
Tasks that breach SLA will still continue their run, but will be included in the SLA report. You can also supply an sla_miss_callback that will be called when the SLA is missed if you want to run your own logic.
Note: We'll be covering the tasks in-depth in a later article.
XComs
XComs (short for “cross-communications”) are a mechanism that let Tasks talk to each other, as by default Tasks are entirely isolated and may be running on entirely different machines.
An XCom is identified by a
key(essentially its name), as well as thetask_idanddag_idit came from. They can have any (serializable) value, but they are only designed for small amounts of data; do not use them to pass around large values, like dataframes.XComs are explicitly “pushed” and “pulled” to/from their storage using the
xcom_pushandxcom_pullmethods on Task Instances. Many operators will auto-push their results into an XCom key calledreturn_valueif thedo_xcom_pushargument is set toTrue(as it is by default), and@taskfunctions do this as well.
Integration
Kubernetes
You can deploy an airflow environment in a Kubernetes cluster and take advantage of its autoscaling capabilities. Each task could be run on a separate Kubernetes pod. There are some useful resource links in the official docs here.
Listeners
Using Pluggy you can create notifications for the following workflow events:
Lifecycle Events: Regarding jobs
on_startingbefore_stopping
Task Status Change:
on_task_instance_runningon_task_instance_successon_task_instance_failed
Final Words
This concludes all the basic concepts and architecture of Apache Airflow, however creating and maintaining a workflow requires expert practical knowledge, as there are many tips and tricks in regard to how to code the DAGs and how to connect Airflow with other online services.
